반응형
실무에서 아직 jdk1.6을 사용하지만 최신 자바에 대해 공부하는 중 가장 컸던 변화라 생각한 Stream에 대해 정리하고자 한다.
Stream
Stream은 자바8부터 추가된 기능으로 컬렉션, 배열과 같은 자료구조를 함수형 인터페이스(람다)를 적용하며 처리하는 기능입니다. 즉, 데이터를 담고 있는 자료구조(컬렉션)이 아닙니다.
스트림은 '데이터의 흐름'이며 적절한 operation을 통해 데이터를 가공해 원하는 타입으로 제공합니다.
자바8 이전에는 배열이나 컬렉션을 다루기 위해 for 또는 foreach를 통해 하나씩 꺼내서 다뤘습니다. 간단한 경우는 큰 문제가 없었지만 로직이 복잡해지면 코드의 양은 많아지고 향후 유지보수에도 어려움이 발생합니다.
아래 코드는 기존 for문을 사용한 방법과 stream을 사용한 방법의 예시입니다.
import java.util.*;
public class StreamExample{
public static void main(String []args){
List<String> names = new ArrayList<>();
names.add("seungwoo");
names.add("sw");
names.add("jsw");
names.add("java8");
// 자바 8 이전 for문을 사용한 방법
for (int i=0; i<names.size(); i++) {
if (names.get(i).startsWith("s")) {
System.out.println(names.get(i).toUpperCase());
}
}
// stream을 사용한 방법
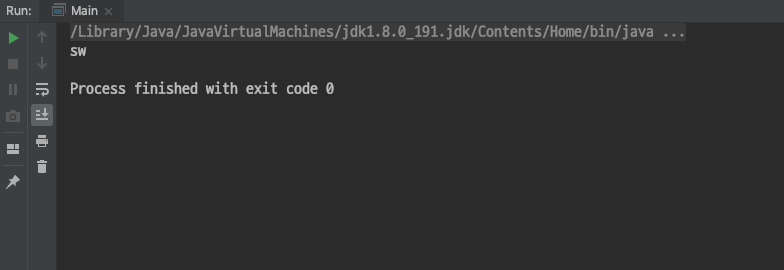
names.stream().filter(name -> name.startsWith("s"))
.map(name -> name.toUpperCase())
.forEach(System.out::println);
}
}위 코드에서 stream을 이용한 방법을보면 메서드 체이닝을 통해 연산을 합니다. 이러한 오퍼레이션은 중개 오퍼레이션, 종료 오퍼레이션 2가지가 존재합니다.
중개 오퍼레이션
- Stream을 리턴함
- Lazy하다
- filter, map, limit, skip, sorted, flatmap...
여기서 lazy하다는 말은 종료 오퍼레이션이 나오기 전까지는 실행하지 않는 것을 뜻합니다. 즉 결과가 필요하기 전까지 연산의 시점을 최대한 늦추는것을 뜻합니다.
List<String> names = new ArrayList<>();
names.add("seungwoo");
names.add("sw");
names.add("jsw");
names.add("java8");
// list의 내용을 바꾸지 않고 단지 stream으로 가지고 있음
// 중계 operation, 종료 operation이 있음
// 중계 operation는 기본적으로 lazy한데 중계 operation은 stream을 리턴하며 종료 operation은 stream이 아닌 다른타입을 리턴함.
Stream<String> stream = names.stream()
.map(String::toUpperCase);이처럼 종료 오퍼레이션이 없는경우 연산을 하지 않습니다.
종료 오퍼레이션
- Stream을 리턴하지 않음
- collect, allMatch, count, forEach, min, max...
List<String> names = new ArrayList<>();
names.add("seungwoo");
names.add("sw");
names.add("jsw");
names.add("java8");
long count = names.stream()
.filter(name -> name.startsWith("s"))
.count();
System.out.println(count);종료 오퍼레이션이 있는경우 연산이 실행됩니다.
반응형
'Java' 카테고리의 다른 글
| [JAVA] Pattern과 Matcher(정규표현식) (0) | 2020.07.01 |
|---|---|
| [JAVA] 웹 크롤링 - Jsoup을 사용한 실시간 데이터 수집 (0) | 2020.06.16 |
| [Java] Comparable / Comparator의 차이 (0) | 2020.05.27 |
| [Java] toString()과 String.valueOf()의 차이점 (4) | 2019.04.23 |
| [Java] 람다표현식 기초 (JAVA 8) (0) | 2019.01.28 |